3장 동작모드
동작 모드에대한 고찰
nvpmodel 명령어
Jetpack을 설치해서 동작하면 기본 Default mode는 Mode ID=2로 15W로 동작하게 된다.
아래는 주요 명령어들이다.
sudo nvpmodel -q (for current mode)자세히 보고 싶으면--verboseoption 추가sudo nvpmodel -m 0 (for changing mode, persists after reboot)sudo ~/tegrastats (for monitoring clocks & core utilization)
각각의 모드들에 대한 소비전력과 성능은 아래의 표와 같다.
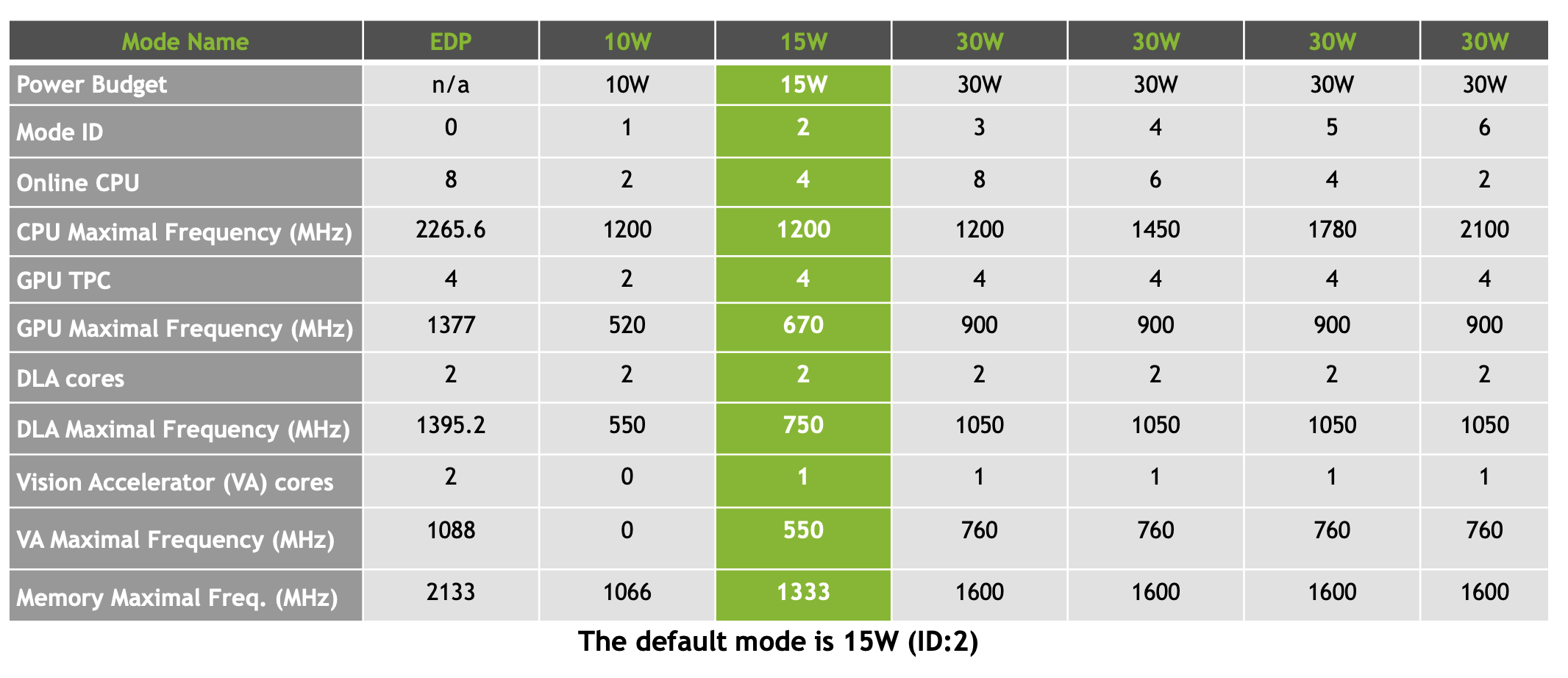
모드를 적용 시키기 위해선 재부팅을 해야한다.
jetson_clocks.sh
jetson_clocks.sh 스크립트를 통해서 현재의 nvpmodel mode에서의 최고의 성능을 달성 할 수 있다. DVFS로 동작하는것을 방지하기 때문이다.
아래와 같이 세가지 동작 옵션을 내장하고 있다.
--show를 통해서 현재 상태를 알 수 있다.
nvpmodel과 다르게 이건 reboot하면 유지되지 않는다.
최고 성능으로 동작 시키기
Installing TensorFlow on Xavier
설치가능한 framework들은 아래와 같다. https://developer.qa.nvidia.com/deep-learning-frameworks
공식적인 설치 절차 https://docs.nvidia.com/deeplearning/dgx/install-tf-xavier/index.html
python 3.6으로 설치했다.
사전 설치 단계
Install JetPack 4.1.1 Developer Preview
Install HDF5
apt-get install libhdf5-serial-dev hdf5-tools
Install pip3 (python3.6)
Install the following packages:
pip3로 패키지 설치시 생각보다 엄청 오래걸리므로 절대로
Ctrl+C하지말고 기다리면 언젠간 설치된다.
최종결과
Tensorflow-gpu 설치 및 확인
Installing TensorFlow
pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v411 tensorflow-gpu미리 nvidia에서 사전에 빌드해둔 것이https://developer.download.nvidia.com/compute/redist/jp/v411/tensorflow-gpu/에 있다. 이것을 다운받아서 설치하는 명령어이다. 현재 가장 최신 stable 버전을 포함한다.
tensorflow-gpu 설치완료
설치 확인 아래와 같이 나오면 설치가 완료
MNIST데이터를 이용한 CNN 모델 학습 시간 분석
이전 포스트에서 여러 GPU들과 비교 했었다. 같은 코드로 Jetson Xaiver보드도 대략적으로 테스트 해본다.
사용한 코드는 이전처럼 아래 git에 있다. https://github.com/leejaymin/TensorFlowLecture/tree/master/5.CNN
deafult mode = 2로 실험한 결과 아래와 같다.
최고성능 모드: mode = 0, jetson_clock.sh
결론적으로 생각보다 느리다. 아래와 같은 수준이다. 이론상 performance는 32-TOPS이다. 기존 다른 NVIDIA tegra 계열이나 1080 또는 2080 계열은 이론상 FLOPS로 표기한다.
결국 아래 성능 차이는 아래와 같다.
GTX 970<Jetson-Xaiver<1060<1080<P100
TOPS와 TFLOPS와의 차이점
TOPS are Tera operations per second, i.e. 1 trillion operations (integer, float, etc.) each second.
TFLOPS are Tera floating point operations per second, i.e. 1 trillion (usually single precision) floating point operations per second.
Last updated
Was this helpful?